| |
| |
| Investigating Corrupt/Malicious PDF Document |
| Author:
Ayush Anand |
| |
| |
| |
|
|
|
| |
| |
| |
|
|
| |
| |
|

|
Today, I will show you how to analyze and troubelshoot a corrupted
or malicious PDF document. In this exercise I will be using sample
PDF file for illustration purposes which you can download from here
[Reference 2]. Before
proceeding further, it is highly recommended that you to read this
article 'PDF Overview - Peering into the Internals of PDF'
[Reference 1]
for better understanding of internal structure and components of
PDF.
|
|
|
|
|
This article will help you get better understanding of inner working
and flow of PDF file assisting you in the PDF Malware
Analysis or any research work revolving around PDF. |
| |
| |
| |
|
| Before we get our hands dirty, we need to have following tools |
- Acrobat Reader
- Notepad++ or any other text editor
|
|
|
| |
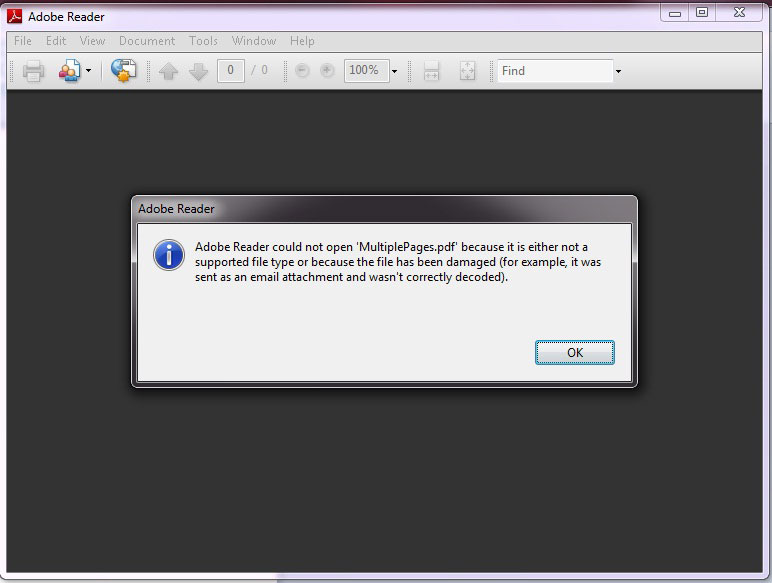
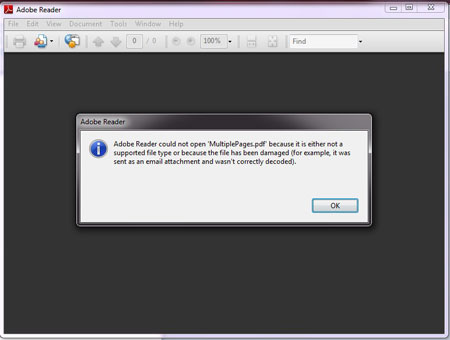
Now download the sample document 'multipages.pdf'
[References 2] and open it in the PDF reader.
On launching you will see following error |
| |
 |
| |
| |
| |
| |
Lets start the investigation as to see
what went wrong with this PDF document.
To get inside view,
open this corrupt PDF file in Notepad++. You will see the
contents as shown below
|
| |
|
1
0 obj
<<
/Pages
2 0
R
/Type
/Catalog
>>
endobj
2
0 obj
<<
/Count
2
/Kids
[ 3
0 R 5
0 R 7
0 R 9
0 R
11 0 R
]
/Type
/Pages
>>
endobj
3
0 obj
<<
/MediaBox
[ 0
0 795
842 ]
/Parent
2 0
R
/Contents
4 0
R
/Resources
<<
/Font
<<
/F1
<<
/Name
/F1
/BaseFont
/Helvetica
/Subtype
/Type1
/Type
/Font
>>
>>
>>
/Type
/Page
>>
endobj
4
0 obj
<<
/Length
55
>>stream
BT
/F1
18 Tf
186
690 Td
20
TL
(www.secsavvy.com)
Tj
ET
endstream
endobj
5
0 obj
<<
/MediaBox
[ 0
0 795
842 ]
/Parent
2 0
R
/Contents
6 0
R
/Resources
<<
/Font
<<
/F1
<<
/Name
/F1
/BaseFont
/Helvetica
/Subtype
/Type1
/Type
/Font
>>
>>
>>
/Type
/Page
>>
endobj
6
0 obj
<<
/Length
45
>>stream
BT
/F1
15 Tf
186
690 Td
20
TL
(Page
1) Tj
ET
endstream
endobj
7
0 obj
<<
/MediaBox
[ 0
0 795
842 ]
/Parent
2 0
R
/Contents
8 0
R
/Resources
<<
/Font
<<
/F1
<<
/Name
/F1
/BaseFont
/Helvetica
/Subtype
/Type1
/Type
/Font
>>
>>
>>
/Type
/Page
>>
endobj
8
0 obj
<<
/Length
45
>>stream
BT
/F1
15 Tf
186
690 Td
20
TL
(Page
2) Tj
ET
endstream
endobj
9
0 obj
<<
/MediaBox
[ 0
0 795
842 ]
/Parent
2 0
R
/Contents
10 0
R
/Resources
<<
/Font
<<
/F1
<<
/Name
/F1
/BaseFont
/Helvetica
/Subtype
/Type1
/Type
/Font
>>
>>
>>
/Type
/Page
>>
endobj
10
0 obj
<<
/Length
45
>>stream
BT
/F1
15 Tf
186
690 Td
20
TL
(Page
3) Tj
ET
endstream
endobj
11
0 obj
<<
/MediaBox
[ 0
0 795
842 ]
/Parent
2 0
R
/Content
12 0
R
/Resources
<<
/Font
<<
/F1
<<
/Name
/F1
/BaseFont
/Helvetica
/Subtype
/Type1
/Type
/Font
>>
>>
>>
/Type
/Page
>>
endobj
12
0 obj
<<
/Length
47
>>stream
BT
/F1
15 Tf
186
690 Td
20
TL
(Password)
Tj
ET
endstream
endobj
xref
0
13
0000000000
65535 f
0000000010
00000 n
0000000067
00000 n
0000000161
00000 n
0000000398
00000 n
0000000510
00000 n
0000000747
00000 n
0000000849
00000 n
0000001086
00000 n
0000001188
00000 n
0000001426
00000 n
0000001529
00000 n
0000001768
00000 n
trailer
<<
/Root
1 0 R
/Size
13
>>
startxref
1873
%%EOF |
| |
| |
| PDF file consists of 4 elements: |
- PDF header identifying the PDF specification.
- A body containing the objects that make up the
document contained in the file
- A cross-reference table containing information about
the indirect objects in the file
- A trailer giving the location of the cross-reference
table and of certain special objects within the body of the
file.
|
| But here if you observe closely,
there is no header so we will add a PDF header and try to open this
PDF. |
| |
| %PDF-1.7 |
| |
| Lets add this missing header info at the
beginning of the file. Now you can open it open it without problem
as shown below. |
| |
 |
| |
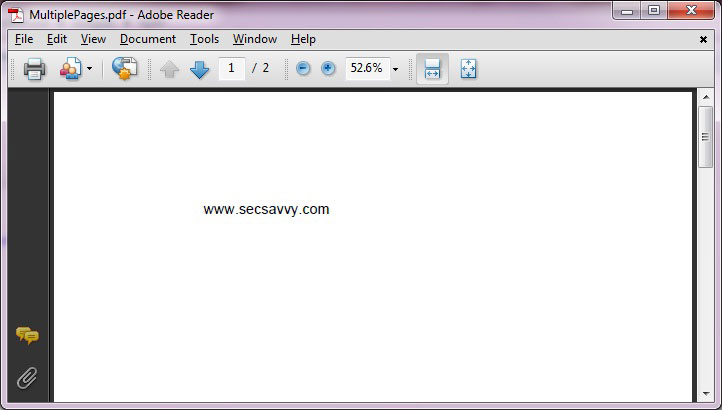
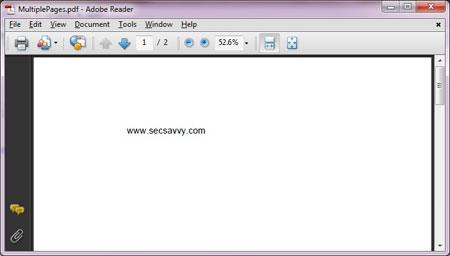
Well that's good, but everything is not
right. From the above picture you can see that it has total of 2
pictures. Lets investigate further.
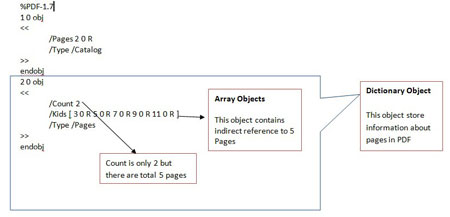
Here is the screenshot
showing the brief analysis of page-linking structure of this PDF
file |
| |
 |
| |
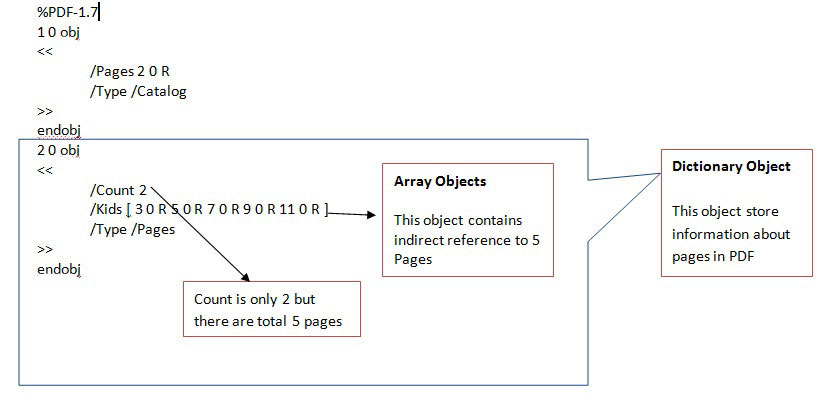
| Now, we are able to find that this PDF has
actually total 5 pages so edit the Count from 2 to 5 and open this
PDF as shown below. |
| |
%PDF-1.7
1 0 obj
<<
/Pages 2 0 R
/Type /Catalog
>>
endobj
2
0 obj
<<
/Count 5
/Kids [ 3 0 R 5 0 R 7 0
R 9 0 R 11 0 R ]
/Type /Pages
>>
endobj |
| |
Now, we are able to see all 5 pages but
last page is blank so we will investigate further.
Last page
is in fact pointed by 11 0 R indirect object reference clear from
the code snippet below |
| |
11 0 obj
<<
/MediaBox [ 0 0 795 842 ]
/Parent 2 0 R
/Content 12 0 R
/Resources <<
/Font <<
/F1 <<
/Name /F1
/BaseFont
/Helvetica
/Subtype /Type1
/Type /Font
>>
>>
>>
/Type /Page
>>
endobj |
| |
In PDF, 'Contents'
keyword is used for describing the contents of a file . If this
entry is absent then the page is empty.
But here object
number 12 Contents is written as 'Content' (note
the missing 's' at the end). Hence the PDF reader is unable to
recognize the name Content so it ignores the Content without giving
any error.
To fix this, simply replace Content with
Contents and open the PDF. Now you will be able to see all
five pages.
You can download this fixed PDF
'MultiplePages_Fixed' [Reference 2]
and test it for yourself. |
| |
| |
| |
| |
| Here is the video demonstration of this entire
analysis and fixing process. |
| |
|
|
| |
| |
| |
| |
- PDF Overview - Peering into the
Internals of PDF
- Download
Sample PDF File
- PDF resources on
Didier Stevens Blog
|
| |
| |
| |
IHope you enjoyed this article and also
got to know more about working flow of PDF document.
f you
are more interested to read about PDF then I recommend you to visit
excellent bog of Didier Stevens
[Reference 3] |
| |
| |
| |
|
|
|
| |
| |
| |
| |
| |